Setup and Installation Guide
Browser Support #
By default, the Yavin UI supports the most recent versions of the following browsers:
- Chrome
- Firefox
- Safari
- IE 11
This may be customized via the app’s config/targets.js file. More information on this file can be found here.
Database Support #
Elide analytic APIs generate SQL queries against your target database(s). Elide must be configured with a Dialect to correctly generate native SQL that matches the database grammar. Elide supports the following dialects by default:
- H2
- Hive
- Presto
- Druid
- MySQL
- Postgres
More information on dialects and how to use them can be found here.
As part of cloning the repo, all the appropriate and latest drivers will be pulled for all the different dialects supported by Yavin:
Out of the box you will have an entry for the H2 dialect. To link to a new dialect, you will have to update this file and add another entry for another database.
H2 is still used for Yavin/Navi metadata tables so you should not remove H2.
Semantic Models #
A semantic model is the view of the data you want your users to understand. It is typically non-relational (for simplicity) and consists of concepts like tables, measures, and dimensions. End users refer to these concepts by name only (they are not expected to derive formulas or know about the physical storage or serialization of data).
A virtual semantic layer maps a semantic model to columns and tables in a physical database. Yavin leverages Elide’s virtual semantic layer which accomplishes this mapping through a HJSON configuration language. HJSON is a human friendly adaptation of JSON that allows comments and a relaxed syntax among other features. Elide’s virtual semantic layer includes the following information:
- The defintions of tables, measures, and dimensions you want to expose to the end user.
- Metadata like descriptions, categories, and tags that better describe and label the semantic model.
- For every table, measure, and dimension, a SQL fragment that maps it to the physical data. These fragements are used by elide to generate native SQL queries against the target database.
More information on Elide’s analytic query support and virtual semantic layer can be found here.
Writing your first semantic model #
Elide provides its own guide for getting started that includes setting up a simle semantic model. The following sections will illustrate how Yavin is configured to explore Netflix movie and TV show titles.
Connections, Tables, Dimensions, Measures and Joins #
When running locally, Yavin will leverage the H2 in-memory database. The connection configuration looks like:
{
dbconfigs: [
{
# We created the connection for the demo using H2 connection
name: DemoConnection
url: jdbc:h2:mem:DemoDB; DB_CLOSE_DELAY=-1; INIT=RUNSCRIPT FROM 'classpath:create-demo-data.sql'
driver: org.h2.Driver
user: guest
dialect: H2
}
]
}
Yavin’s demo data includes a single table in its semantic model NetflixTitles:
{
tables: [
{
# The API name
name: NetflixTitles
# The name presented in the UI
friendlyName: Netflix Titles
# The physical table where the data lives.
table: netflix_titles
# The database to run queries against
dbConnectionName: DemoConnection
# The list of dimensions
dimensions: [
{
# The API name of the dimension.
name: title_id
# The name of the dimension presented in the UI
friendlyName: Title Id
category: Attributes
# The data type
type: TEXT
# A templated SQL fragment that fetches this dimension. 'title_id' here is the physical database column name.
definition: ''
}
{
name: show_type
friendlyName: Show Type
category: Attributes
type: TEXT
definition: ''
}
{
name: title
friendlyName: Title
category: Attributes
type: TEXT
definition: ''
}
{
name: director
friendlyName: Director
category: Attributes
type: TEXT
definition: ''
}
{
name: cast
friendlyName: Cast List
category: Attributes
type: TEXT
definition: ''
}
{
name: country
friendlyName: Countries
category: Attributes
type: TEXT
definition: ''
}
{
name: date_available
category: Date
type: TIME
definition: ''
grains: [
{
type: DAY
}
{
type: YEAR
}
]
}
{
name: release_year
category: Date
type: TIME
definition: ''
grains: [
{
type: YEAR
}
]
}
{
name: film_rating
friendlyName: Film Rating
category: Attributes
type: TEXT
definition: ''
}
{
name: genres
friendlyName: Genre
category: Attributes
type: TEXT
definition: ''
}
{
name: description
friendlyName: Description
category: Attributes
type: TEXT
definition: ''
}
]
# The list of measures
measures: [
{
# The API name of the measure.
name: count
# The name of measure dimension presented in the UI
friendlyName: Title Count
category: Stats
# The data type
type: INTEGER
# A templated SQL fragment that fetches this measure. 'title_id' here is the physical database column name.
definition: 'count()'
}
{
name: total_seasons
friendlyName: Total Seasons
category: Stats
type: INTEGER
definition: "sum(cast (case when like '% Seasons' then REPLACE(, ' Seasons', '') else '0' end AS INT))"
}
{
name: movie_duration
friendlyName: Duration (in mins)
category: Stats
type: INTEGER
definition: "sum(cast (case when like '% min' then REPLACE(, ' min', '') else '0' end AS INT))"
}
]
}
]
}
The Netflix demo data only sourced from a single physical table. More complex data models may source from multiple physical tables and require joins at query time. More information about joins can be found here.
User Interface Metadata #
The Yavin UI is metadata driven and will present your semantic model:
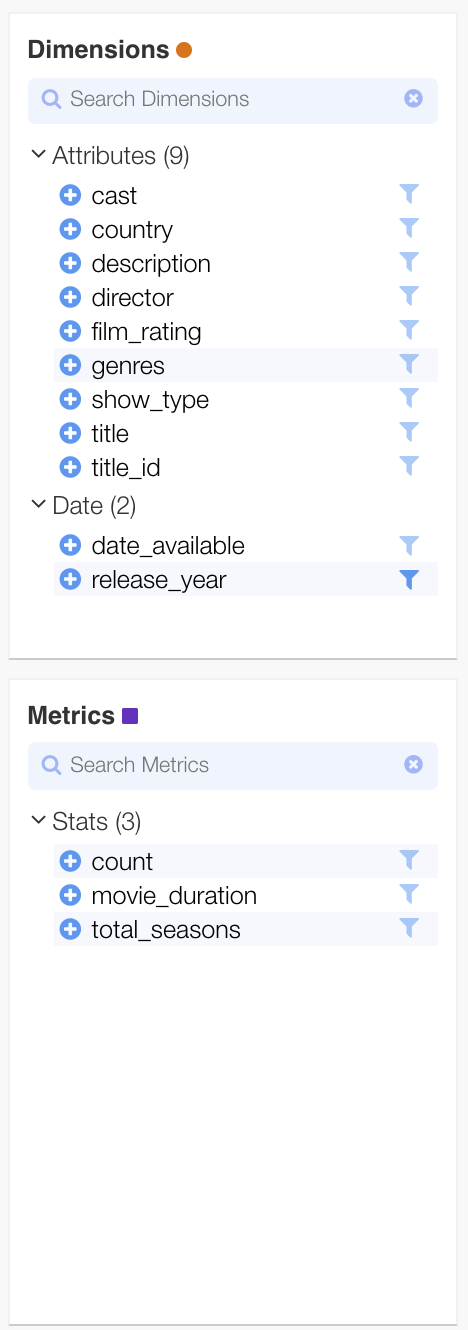
Type Ahead Search #
When constructing filters in the Yavin UI, the search bar can be used to perform type ahead queries in order to suggest dimension values. Type ahead search can be enabled for any dimension of type TEXT in one of two ways. The first is to add a values attribute to the dimension with a list of all possible values. This works well when your dataset does not have a dedicated dimension table and when the set of dimension values is small:
{
name : countryCode
friendlyName : Country ISO Code
type : TEXT
definition : ''
values : ['US', 'HK']
}
When your dataset does have a dedicated dimension table, you can specify an alternate semantic model that can be searched for values by adding the tableSource attribute (a ‘.’ separated expression consisting of two components: the table to search, followed by the column name to search in that table). The Yavin UI will issue separate search queries against this table when the user types in the search bar. The tableSource attribute can be configured to point to a different table or the same table where the dimension is defined.
{
name: countryName
type: TEXT
definition: ''
tableSource: country.name
}
When neither values or tableSource is specified, Yavin will search against the selected fact semantic model.
If your fact table is very large, the type ahead queries may be slow.
Automatically showing filter values #
The Yavin UI will automatically show possible values if the dimension has a cardinality attribute of tiny or small
{
name: countryName
type: TEXT
definition: ''
tableSource: country.name
cardinality: small
}
Yavin Example Key Elements #
The Yavin example project consists of the following key elements :
- HJSON configuration for a H2 in-memory database.
- HJSON configuration for a table (and its respective measures and dimensions).
- A liquibase script that sets up your database with relevant tables needed for Yavin.
- Test data that is initialized in the database.
- [Example integration tests][integration-test] that verify the Yavin APIs are working correctly.
- A Spring boot application configuration file that configures web service routes and other service level controls.
Yavin Detailed Installation Guide #
Here are the complete steps for installing and setting up Yavin with your dataset and your semantic models:
Step 1. Install Yavin Source. #
This step was covered in quick start guide. Upon installation, you will have the Yavin repo on your local machine. Your repo will include the following key subdirectories:
| Path | Purpose |
|---|---|
app/ws/src/main/resources/demo-configs/db/sql |
Your dialect connection can reside here |
app/ws/src/main/resources/demo-configs/models/tables |
Your semantic models can reside here |
app/ws/src/main/resources/application.yaml |
The spring boot configuration file for your application |
app/ws/src/main/kotlin/com/yahoo/yavin/ws/filters |
Directory for web request filters including authentication |
app/ws/src/main/resources/db/changelog/changelog.xml |
Database changelog for setting up the database |
Step 2. Setup Your Database. #
Yavin requires a database to store user information, reports, dashboards, and other application objects. The Yavin repo includes a liquibase-script for creating these tables. The script may require modifications to work with your target database.
Step 3. Configure the Database Connection. #
Add a database configuration file to connect to your database. More information about database configuration files can be found here.
Step 4. Define your Semantic Model. #
Add one or more semantic model definition files. More information about adding tables can be found here.
Step 5. Secure your Semantic Model. #
Yavin allows you to limit access to tables, measures, and dimensions by user role. There are three steps involved:
- Create a security roles file which enumerates the roles your application will have. More information can be found here.
- Update your semantic model, by adding
readAccessrules for tables, measures, and dimensions you want to restrict. These rules can include a single role or a complex security expression with multiple roles joined by logical AND (conjunction), OR (disjunction), and parenthetic groupings. - Yavin stores users and roles in two separate database tables (
userandroles). The roles table must be updated to include all the roles defined in step 1. When a user is added to the database, it must be assigned 1 or more roles.
Yavin also supports row level security. Row level security requires building your application with custom FilterExpressionCheck classes. These classes have names that can be leveraged in readAccess rules similar to roles. More information on custom security checks can be found here.
Step 6. Define an authentication filter for the application. #
Yavin comes bundled with an example filter that authenticates every user as admin. You will want to replace this example with a servlet filter that authenticates your users.
Step 7. Configure Your Application #
Yavin is a spring boot application. The default configuration can be found here. This configuration allows you to change a number of settings including:
- The application port.
- The routes for the APIs.
- Location of liquibase migration scripts (if you run them as part of application boot).
The configuration file has sections including:
The application configuration supports profiles for enabling different settings for different environments.
Step 8. Build Your Application #
To build Yavin as a jar, run the following command:
./gradlew bootJar
Step 9. Validate Semantic Model #
The build creates a fat jar with all dependencies including a tool that can be leveraged to validate your semantic model before deploying or running your service. More details about validating the semantic model can be found here.
Step 10. Run Your Application #
To run Yavin locally, simple execute:
./gradlew bootRun
Step 11. Launch the Application #
Launch Yavin on your browser by loading http://localhost:8080.